[转]Linux 异步IO机制
【转自 http://blog.csdn.net/eroswang/article/details/4095163】
Linux的I/O机制经历了一下几个阶段的演进:
1. 同步阻塞I/O: 用户进程进行I/O操作,一直阻塞到I/O操作完成为止。
2. 同步非阻塞I/O: 用户程序可以通过设置文件描述符的属性O_NONBLOCK,I/O操作可以立即返回,但是并不保证I/O操作成功。
3. 异步事件阻塞I/O: 用户进程可以对I/O事件进行阻塞,但是I/O操作并不阻塞。通过select/poll/epoll等函数调用来达到此目的。
4. 异步时间非阻塞I/O: 也叫做异步I/O(AIO),用户程序可以通过向内核发出I/O请求命令,不用等带I/O事件真正发生,可以继续做
另外的事情,等I/O操作完成,内核会通过函数回调或者信号机制通知用户进程。这样很大程度提高了系统吞吐量。
下面就AIO做详细介绍:
要使用aio的功能,需要include头文件aio.h,在编译连接的时候需要加入POSIX实时扩展库rt.下面就aio库的使用做介绍。
1. AIO整个过程所使用的数据存放在一个结构体中,struct aiocb,aio control block.看看头文件中的定义:
/* Asynchronous I/O control block. */
struct aiocb
{
int aio_fildes; /* File desriptor. */ 需要在哪个文件描述符上进行I/O
int aio_lio_opcode; /* Operation to be performed. */ 这个是针对批量I/O的情况有效,读写操作类型
int aio_reqprio; /* Request priority offset. */ 请求优先级(If _POSIX_PRIORITIZED_IO is defined, and this file supports it, then the
asynchronous operation is submitted at a priority equal to that of the
calling process minus aiocbp->aio_reqprio.)
volatile void *aio_buf; /* Location of buffer. */ 具体内容,数据缓存
size_t aio_nbytes; /* Length of transfer. */ 数据缓存的长度
struct sigevent aio_sigevent; /* Signal number and value. */ 用于异步I/O完成后的通知。
内部实现使用的数据成员。
/* Internal members. */
struct aiocb *__next_prio;
int __abs_prio;
int __policy;
int __error_code;
__ssize_t __return_value;
#ifndef __USE_FILE_OFFSET64
__off_t aio_offset; /* File offset. */
char __pad[sizeof (__off64_t) - sizeof (__off_t)];
#else
__off64_t aio_offset; /* File offset. */ 文件读写偏移
#endif
char __unused[32];
};
2. int aio_read(struct aiocb *aiocbp);
异步读操作,向内核发出读的命令,传入的参数是一个aiocb的结构,比如
struct aiocb myaiocb;
memset(&aiocb , 0x00 , sizeof(myaiocb));
myaiocb.aio_fildes = fd;
myaiocb.aio_buf = new char[1024];
myaiocb.aio_nbytes = 1024;
if (aio_read(&myaiocb) != 0)
{
printf("aio_read error:%s/n" , strerror(errno));
return false;
}
3. int aio_write(struct aiocb *aiocbp);
异步写操作,向内核发出写的命令,传入的参数仍然是一个aiocb的结构,当文件描述符的O_APPEND
标志位设置后,异步写操作总是将数据添加到文件末尾。如果没有设置,则添加到aio_offset指定的
地方,比如:
struct aiocb myaiocb;
memset(&aiocb , 0x00 , sizeof(myaiocb));
myaiocb.aio_fildes = fd;
myaiocb.aio_buf = new char[1024];
myaiocb.aio_nbytes = 1024;
myaiocb.aio_offset = 0;
if (aio_write(&myaiocb) != 0)
{
printf("aio_read error:%s/n" , strerror(errno));
return false;
}
4. int aio_error(const struct aiocb *aiocbp);
如果该函数返回0,表示aiocbp指定的异步I/O操作请求完成。
如果该函数返回EINPROGRESS,表示aiocbp指定的异步I/O操作请求正在处理中。
如果该函数返回ECANCELED,表示aiocbp指定的异步I/O操作请求已经取消。
如果该函数返回-1,表示发生错误,检查errno。
5. ssize_t aio_return(struct aiocb *aiocbp);
这个函数的返回值相当于同步I/O中,read/write的返回值。只有在aio_error调用后
才能被调用。
6. int aio_cancel(int fd, struct aiocb *aiocbp);
取消在文件描述符fd上的aiocbp所指定的异步I/O请求。
如果该函数返回AIO_CANCELED,表示操作成功。
如果该函数返回AIO_NOTCANCELED,表示取消操作不成功,使用aio_error检查一下状态。
如果返回-1,表示发生错误,检查errno.
7. int lio_listio(int mode, struct aiocb *restrict const list[restrict],
int nent, struct sigevent *restrict sig);
使用该函数,在很大程度上可以提高系统的性能,因为再一次I/O过程中,OS需要进行
用户态和内核态的切换,如果我们将更多的I/O操作都放在一次用户太和内核太的切换中,
减少切换次数,换句话说在内核尽量做更多的事情。这样可以提高系统的性能。
用户程序提供一个struct aiocb的数组,每个元素表示一次AIO的请求操作。需要设置struct aiocb
中的aio_lio_opcode数据成员的值,有LIO_READ,LIO_WRITE和LIO_NOP。
nent表示数组中元素的个数。最后一个参数是对AIO操作完成后的通知机制的设置。
8. 设置AIO的通知机制,有两种通知机制:信号和回调
(1).信号机制
首先我们应该捕获SIGIO信号,对其作处理:
struct sigaction sig_act;
sigempty(&sig_act.sa_mask);
sig_act.sa_flags = SA_SIGINFO;
sig_act.sa_sigaction = aio_handler;
struct aiocb myaiocb;
bzero( (char *)&myaiocb, sizeof(struct aiocb) );
myaiocb.aio_fildes = fd;
myaiocb.aio_buf = malloc(BUF_SIZE+1);
myaiocb.aio_nbytes = BUF_SIZE;
myaiocb.aio_offset = next_offset;
myaiocb.aio_sigevent.sigev_notify = SIGEV_SIGNAL;
myaiocb.aio_sigevent.sigev_signo = SIGIO;
myaiocb.aio_sigevent.sigev_value.sival_ptr = &myaiocb;
ret = sigaction( SIGIO, &sig_act, NULL );
信号处理函数的实现:
void aio_handler( int signo, siginfo_t *info, void *context )
{
struct aiocb *req;
if (info->si_signo == SIGIO) {
req = (struct aiocb *)info->si_value.sival_ptr;
if (aio_error( req ) == 0) {
ret = aio_return( req );
}
}
return;
}
(2). 回调机制
需要设置:
myaiocb.aio_sigevent.sigev_notify = SIGEV_THREAD
my_aiocb.aio_sigevent.notify_function = aio_handler;
回调函数的原型:
typedef void (* FUNC_CALLBACK)(sigval_t sigval);
AIO机制为服务器端高并发应用程序提供了一种性能优化的手段。加大了系统吞吐量。
[转]mongodb地理位置索引实现原理
【转自 http://blog.csdn.net/eroswang/article/details/7106308】
地理位置索引支持是MongoDB的一大亮点,这也是全球最流行的LBS服务foursquare 选择MongoDB的原因之一。我们知道,通常的数据库索引结构是B+ Tree,如何将地理位置转化为可建立B+Tree的形式,下文将为你描述。
首先假设我们将需要索引的整个地图分成16×16的方格,如下图(左下角为坐标0,0 右上角为坐标16,16):

单纯的[x,y]的数据是无法建立索引的,所以MongoDB在建立索引的时候,会根据相应字段的坐标计算一个可以用来做索引的hash值,这个值叫做geohash,下面我们以地图上坐标为[4,6]的点(图中红叉位置)为例。
我们第一步将整个地图分成等大小的四块,如下图:

划分成四块后我们可以定义这四块的值,如下(左下为00,左上为01,右下为10,右上为11):
| 01 | 11 |
| 00 | 10 |
这样[4,6]点的geohash值目前为 00
然后再将四个小块每一块进行切割,如下:
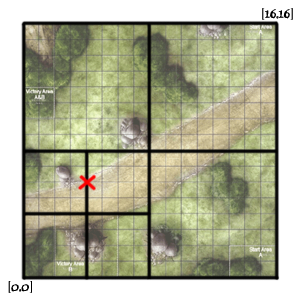
这时[4,6]点位于右上区域,右上的值为11,这样[4,6]点的geohash值变为:0011
继续往下做两次切分:

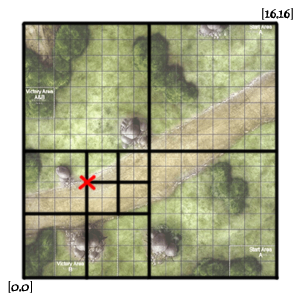
最终得到[4,6]点的geohash值为:00110100
这样我们用这个值来做索引,则地图上点相近的点就可以转化成有相同前缀的geohash值了。
我们可以看到,这个geohash值的精确度是与划分地图的次数成正比的,上例对地图划分了四次。而MongoDB默认是进行26次划分,这个值在建立索引时是可控的。具体建立二维地理位置索引的命令如下:
db.map.ensureIndex({point : "2d"}, {min : 0, max : 16, bits : 4})
其中的bits参数就是划分几次,默认为26次。
CHROME插件 “复制选中的链接地址”
昨日本来在人人影视上面下载美剧,结果那部电视剧太多集了。CHROME下那个复制全部不能用。只好自己写一个。
代码如下:
注册文件 manifest.json
{
"name": "复制选中的链接地址",
"description": "复制选中的链接地址到剪贴板中(电驴,离线什么的)",
"version": "0.1",
"permissions": ["contextMenus","tabs","https://*/*","http://*/*"],
"background_page": "background.html"
}
实现选中链接文件(之前对CHROME也没有什么了解,临时从chrome API那里下载的一个例子,文件名忘改了) sample.js
var selection = window.getSelection();
if(selection.rangeCount > 0)
{
var range = selection.getRangeAt(0);
var div = document.createElement('div');
//把复制的内容放入div中,转化为DOM结构
div.appendChild(range.cloneContents());
var contents = "";
//获取div里面的,链接元素
var aucher_list = div.getElementsByTagName("a");
for (var i = 0; i < aucher_list.length; i++) {
contents += "\n" + aucher_list[i].href;
}
contents = contents.substring(1);
//向background发送ED2K链接
chrome.extension.sendRequest({text:contents});
}
background.js
<html>
<head>
<meta http-equiv="content-type" content="text/html; charset=utf-8">
<title>Background</title>
<script type="text/javascript" charset="utf-8">
chrome.extension.onRequest.addListener(function (msg, sender, sendResponse) {
var textarea = document.getElementById("lnktext");
textarea.value = msg.text;
textarea.select();
document.execCommand("copy", false, null);
sendResponse({});
}
);
function copylinkbyselected(info,tab){
chrome.tabs.executeScript(null, { "file" : "sample.js", "allFrames" : true } );
}
chrome.contextMenus.create(
{
"title": "copy link by selected",
"contexts":["selection"],
"type":"normal",
"onclick": copylinkbyselected
});
</script>
</head>
<body>
<textarea id="lnktext" rows="8" cols="40"></textarea>
</body>
</html>
JBPM4 使用MYSQL作为后端,执行结束流程报错。
首先,分析配置文件hibernate.cfg.xml的内容,其中在默认设置是用 HSQL(开源的数据库),这是一个内存数据库,这种内存数据库用来代替项目实际所用的数据库来做单元测试挺不错的。不过在我们的真实开发中,还是使用oracle等。
MySQL 的更改如下:
<property name="hibernate.dialect">org.hibernate.dialect.MySQLDialect</property>
<property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property>
<property name="hibernate.connection.url">jdbc:mysql://localhost:3306/onlineas</property>
<property name="hibernate.connection.username">root</property>
<property name="hibernate.connection.password">123456</property>
运行junit测试,抛异常
07:48:16,655 INF | [DefaultCommandService] exception while executing command org.jbpm.pvm.internal.cmd.DeleteDeploymentCmd@8a2023
org.hibernate.exception.ConstraintViolationException: could not delete: [org.jbpm.pvm.internal.model.ExecutionImpl#10]
....
Caused by: com.mysql.jdbc.exceptions.MySQLIntegrityConstraintViolationException: Cannot delete or update a parent row: a foreign key constraint fails (`onlineas/jbpm4_execution`, CONSTRAINT `FK_EXEC_INSTANCE` FOREIGN KEY (`INSTANCE_`) REFERENCES `jbpm4_execution` (`DBID_`))
解决办法:修改dialect即可,<property name="hibernate.dialect">org.hibernate.dialect.MySQLInnoDBDialect</property>
oracle嵌套事务(以及触发器中使用复杂查询)
AUTONOMOUS TRANSACTION(自治事务)的介绍 (转:原始连接 http://www.blogjava.net/jesenblog/articles/188249.html)
在基于低版本的ORACLE做一些项目的 过程中,有时会遇到一些头疼的问题.,比如想在执行当前一个由多个DML组成的transaction(事务)时,为每一步DML记录一些信息到跟踪表 中,由于事务的原子性,这些跟踪信息的提交将决定于主事务的commit或rollback. 这样一来写程序的难度就增大了, 程序员不得不把这些跟踪信息记录到类似数组的结构中,然后在主事务结束后把它们存入跟踪表.哎,真是麻烦!
有没有一个简单的方法解决类似问题呢?
ORACLE8i的AUTONOMOUS TRANSACTION(自治事务,以下AT)是一个很好的回答。
AT 是由主事务(以下MT)调用但是独立于它的事务。在AT被调用执行时,MT被挂起,在AT内部,一系列的DML可以被执行并且commit或rollback.
注意由于AT的独立性,它的commit和rollback并不影响MT的执行效果。在AT执行结束后,主事务获得控制权,又可以继续执行了。
如何实现AT的定义呢?我们来看一下它的语法。其实非常简单。
只需下列PL/SQL的声明部分加上PRAGMA AUTONOMOUS_TRANSACTION 就可以了。
1. 顶级的匿名PL/SQL块
2. Functions 或 Procedure(独立声明或声明在package中都可)
3. SQL Object Type的方法
4. 触发器。
比如:
在一个独立的procedure中声明AT
CREATE OR REPLACE PROCEDURE
Log_error(error_msg IN VARCHAR2(100))
IS
PRAGMA AUTONOMOUS_TRANSACTION;
BEGIN
Insert into Error_log values ( sysdate,error_msg);
COMMIT;
END;
oracle 含有lob的字段的时候,无法distinct
在oracle里面有一个这样的设定。在有lob类字段的时候是不可以distinct的。
原因是 lob字段存储的是定位器,不能有distinct操作的。
解决这个问题可以用dbms_lob.substr(column,length)来,转换LOB到VARCHAR
例如: dbms_lob.substr(t.SUPPORT_CONTENT,10000) SUPPORT_CONTENT
这是我在这里的第一篇文章
这是我在这里的第一篇文章。主要是说明这个BLOG对于我而言的定位。
我主要会把这里作为我平时工作和学习中遇到的问题做一个总汇,或者分享一些技术类的文章。
(结束)